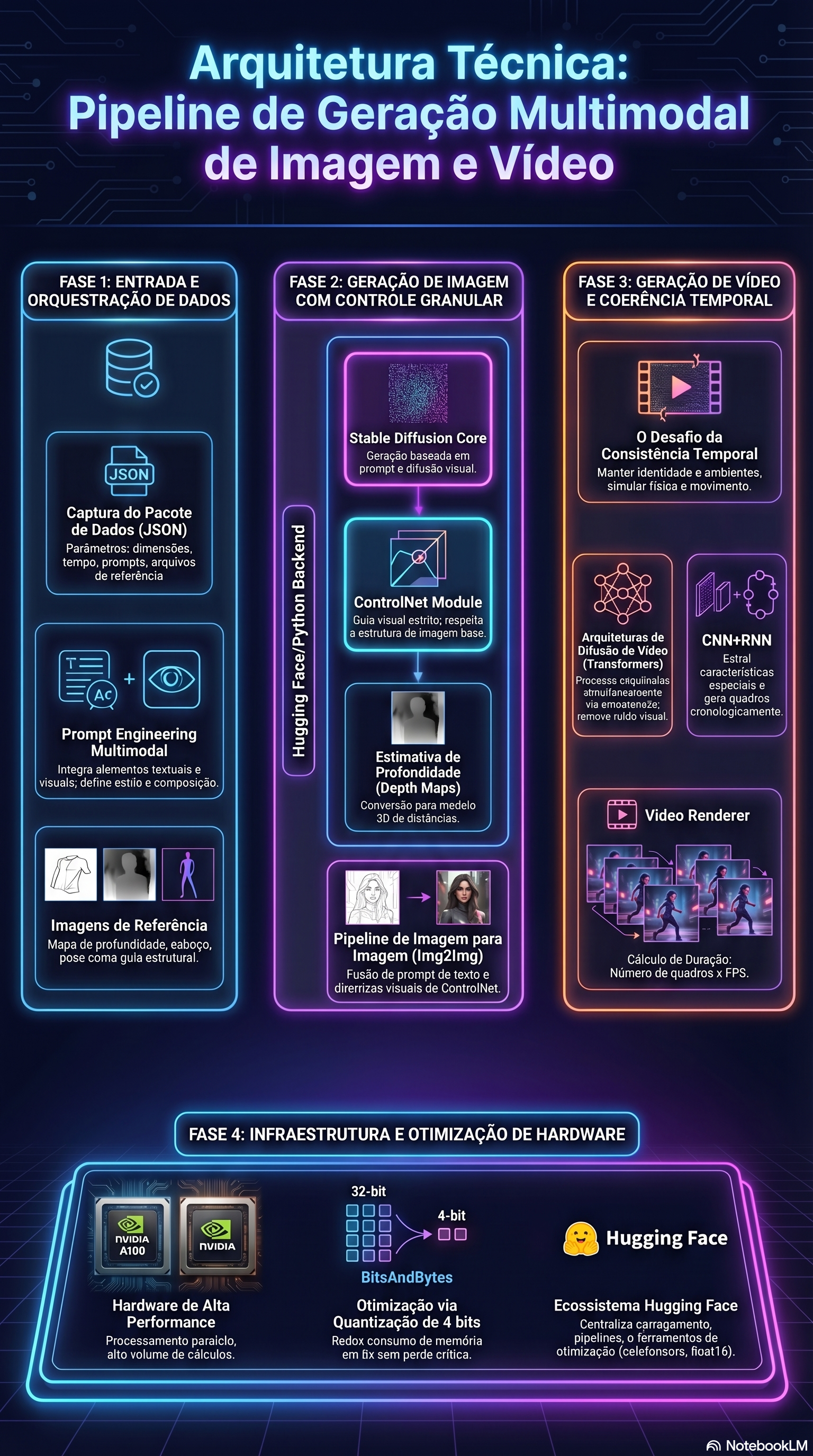
Multimodal Architecture
Design the system around context, control, coherence, and hardware reality.
This page packages your technical guide into a polished web view, connecting product vision to
deployable system design for image and video generation.
1. Base Models
Transformers dominate global context, but the implementation layer matters.
For modern video generation, a more current framing is diffusion with space-time modules, 3D
U-Nets, temporal attention, and increasingly Diffusion Transformers rather than classic CNN+RNN
pipelines alone.
2. Structural Control
ControlNet is a conditioning path, not a replacement model.
Use structural priors such as depth, pose, sketches, or edges to anchor composition while the
diffusion model fills texture, material, and lighting. In practice, control strength and timing
matter as much as the conditioning image itself.
3. Temporal Coherence
Video quality lives in cross-frame consistency, not only in single-frame beauty.
Attention mechanisms give the model longer-range access to motion and identity cues, helping with
character continuity, scene evolution, and more reliable long-form synthesis.
4. GPU Constraints
Quantization reduces weight memory, but total VRAM depends on the whole pipeline.
`load_in_4bit` is useful, especially with FP16 or BF16 compute, but total savings depend on
activations, caches, VAE stages, attention states, and the surrounding runtime.
Artifacts
Included project files